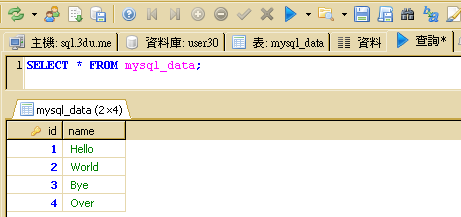
SELECT * FROM mysql_data;由 HDFS 匯出到 mysql_data 資料表的結果:(多出兩筆記錄)
[user00@master ~]$ hadoop fs -mkdir export [user00@master ~]$ cat >> data << EOF 3,Bye 4,Over EOF [user00@master ~]$ hadoop fs -put data export [user00@master ~]$ hadoop fs -cat export/data 3,Bye 4,Over
[user00@master ~]$ export DBID=$USER [user00@master ~]$ sqoop export --connect "jdbc:mysql://localhost/$DBID" --table mysql_data --username $DBID -P --export-dir /user/$(whoami)/export Enter password: 輸入密碼
15/08/05 11:44:56 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 15/08/05 11:44:56 INFO tool.CodeGenTool: Beginning code generation 15/08/05 11:44:57 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `mysql_data` AS t LIMIT 1 15/08/05 11:44:57 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `mysql_data` AS t LIMIT 1 15/08/05 11:44:57 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/lib/hadoop-0.20-mapreduce Note: /tmp/sqoop-user00/compile/13c18cbbdde925b91e52217b9ff48172/mysql_data.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 15/08/05 11:44:58 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-user00/compile/13c18cbbdde925b91e52217b9ff48172/mysql_data.jar 15/08/05 11:44:59 INFO mapreduce.ExportJobBase: Beginning export of mysql_data 15/08/05 11:45:00 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 15/08/05 11:45:00 INFO input.FileInputFormat: Total input paths to process : 1 15/08/05 11:45:00 INFO input.FileInputFormat: Total input paths to process : 1 15/08/05 11:45:00 INFO mapred.JobClient: Running job: job_201508050909_0005 15/08/05 11:45:01 INFO mapred.JobClient: map 0% reduce 0% 15/08/05 11:45:13 INFO mapred.JobClient: map 100% reduce 0% 15/08/05 11:45:15 INFO mapred.JobClient: Job complete: job_201508050909_0005 15/08/05 11:45:15 INFO mapred.JobClient: Counters: 24 15/08/05 11:45:15 INFO mapred.JobClient: File System Counters 15/08/05 11:45:15 INFO mapred.JobClient: FILE: Number of bytes read=0 15/08/05 11:45:15 INFO mapred.JobClient: FILE: Number of bytes written=777660 15/08/05 11:45:15 INFO mapred.JobClient: FILE: Number of read operations=0 15/08/05 11:45:15 INFO mapred.JobClient: FILE: Number of large read operations=0 15/08/05 11:45:15 INFO mapred.JobClient: FILE: Number of write operations=0 15/08/05 11:45:15 INFO mapred.JobClient: HDFS: Number of bytes read=602 15/08/05 11:45:15 INFO mapred.JobClient: HDFS: Number of bytes written=0 15/08/05 11:45:15 INFO mapred.JobClient: HDFS: Number of read operations=19 15/08/05 11:45:15 INFO mapred.JobClient: HDFS: Number of large read operations=0 15/08/05 11:45:15 INFO mapred.JobClient: HDFS: Number of write operations=0 15/08/05 11:45:15 INFO mapred.JobClient: Job Counters 15/08/05 11:45:15 INFO mapred.JobClient: Launched map tasks=4 15/08/05 11:45:15 INFO mapred.JobClient: Data-local map tasks=4 15/08/05 11:45:15 INFO mapred.JobClient: Total time spent by all maps in occupied slots (ms)=31157 15/08/05 11:45:15 INFO mapred.JobClient: Total time spent by all reduces in occupied slots (ms)=0 15/08/05 11:45:15 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 15/08/05 11:45:15 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 15/08/05 11:45:15 INFO mapred.JobClient: Map-Reduce Framework 15/08/05 11:45:15 INFO mapred.JobClient: Map input records=2 15/08/05 11:45:15 INFO mapred.JobClient: Map output records=2 15/08/05 11:45:15 INFO mapred.JobClient: Input split bytes=551 15/08/05 11:45:15 INFO mapred.JobClient: Spilled Records=0 15/08/05 11:45:15 INFO mapred.JobClient: CPU time spent (ms)=5840 15/08/05 11:45:15 INFO mapred.JobClient: Physical memory (bytes) snapshot=619773952 15/08/05 11:45:15 INFO mapred.JobClient: Virtual memory (bytes) snapshot=6384812032 15/08/05 11:45:15 INFO mapred.JobClient: Total committed heap usage (bytes)=942931968 15/08/05 11:45:15 INFO mapreduce.ExportJobBase: Transferred 602 bytes in 15.9262 seconds (37.7992 bytes/sec) 15/08/05 11:45:15 INFO mapreduce.ExportJobBase: Exported 2 records.
SELECT * FROM mysql_data;由 HDFS 匯出到 mysql_data 資料表的結果:(多出兩筆記錄)